Engineering Philosophy: Andrej Karpathy, The Stack You Don't Write

Key Takeaways
- Software 2.0 is Karpathy’s reframe: a neural network is a program compiled from data, not written by hand. The dataset is the source code; training is the compiler.
- He earns the right to that claim by building every layer from scratch – micrograd, char-rnn, nanoGPT – because you cannot trust a stack you can’t rebuild yourself.
- He treats teaching as craft: the legible demo and the clean repo are how he debugs his own understanding, not how he markets it.
- The discipline that connects all of it is the from-scratch principle – implement backpropagation by hand once, and a real model’s failure becomes something you know instead of guess.
The Principle
“Neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we develop software. They are Software 2.0.” – Andrej Karpathy1
Most engineers in 2017 treated neural networks as one more tool in the box – a classifier you reached for when logistic regression wasn’t enough. Karpathy argued they were something else entirely: a new programming paradigm. In Software 1.0, a human writes explicit instructions in Python or C++. In Software 2.0, the human writes a rough skeleton – a network architecture – and curates a dataset, and “the process of training the neural network compiles the dataset into the binary.”1 No human writes the weights. The program is grown, not authored.
One reframing reorganizes everything downstream. If the model is the program, the dataset becomes the source code, the loss curve becomes the compiler error, and the engineer’s job moves from writing logic to shaping the conditions under which logic emerges. The same shift makes context, not code, the real architecture of a modern AI system: you don’t instruct the behavior, you build the substrate it forms in. And underneath all of Karpathy’s teaching runs one conviction – you cannot trust a stack you can’t build yourself. So he built every layer from scratch, in public, one character of backpropagation at a time.
Context
Andrej Karpathy was born in Bratislava, Slovakia, in 1986, and moved with his family to Toronto at fifteen. He studied computer science and physics at the University of Toronto, where – as an undergraduate – he sat in on Geoffrey Hinton’s class and reading groups, absorbing the neural-network gospel years before it became orthodoxy. After a master’s at the University of British Columbia, he went to Stanford for a PhD under Fei-Fei Li at the Stanford Vision Lab, finishing in 2015. His doctoral work sat at the intersection of computer vision and natural language – teaching machines to describe images – the exact seam that the following decade would tear open.2
At Stanford he designed and taught CS231n, the university’s first deep-learning course, which grew from 150 students in 2015 to 750 by 2017.3 He was a founding member of OpenAI in 2015. In 2017 he became Tesla’s Director of AI, reporting to Elon Musk, where he ran the Autopilot vision stack. He returned to OpenAI in 2023, left in 2024 to found the AI-education company Eureka Labs, and in 2026 joined Anthropic’s pretraining team.2 The throughline across every move is not the employer. It is the insistence on understanding the machine all the way down, and then showing everyone else how.
The Work
“The Unreasonable Effectiveness of Recurrent Neural Networks” (2015): The Demo as Argument
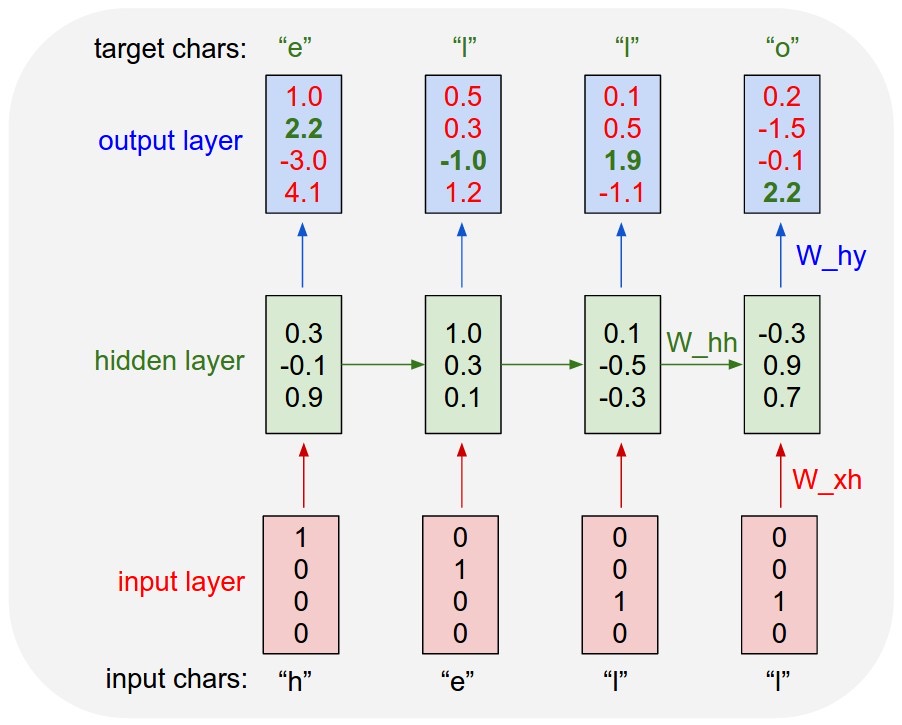
In May 2015, Karpathy published a blog post that went viral in a field that did not yet have viral blog posts. He trained character-level recurrent neural networks – char-rnn – on raw text and let them generate one character at a time. The models learned to produce Shakespeare, LaTeX math that almost compiled, Linux kernel C, and Wikipedia markup, having never been told what any of those things were.4
The post was an argument disguised as a demo. By making a small model do something startling and legible – you could read the gibberish slowly cohering into syntax – Karpathy proved that sequence models had absorbed deep structure from data alone. The accompanying char-rnn code on GitHub mattered as much as the prose. The lesson that would define his career was already present: the strongest case for an idea is the smallest working version of it, with the code attached.
Software 2.0 (2017): The Reframe
The 2017 essay is the keystone. Karpathy’s claim was that for a growing class of problems – vision, speech, translation – it is easier to collect data and train a network than to write the program by hand, and the trained network is often better. Software 2.0 is “written in much more abstract, human unfriendly language, such as the weights of a neural network,” and “no human is involved in writing this code.”1
The essay’s real contribution was cultural, not just technical. If neural nets are a programming paradigm, then teams need version control for datasets, debuggers for activations, and a discipline for failure modes the old stack never had. Nearly a decade later Karpathy extended the framing to Software 3.0: large language models you program in plain English, which is why he could call English “the hottest new programming language.”5 The agent didn’t get smarter – the substrate did, and the engineering moved up a layer each time.
Tesla Autopilot (2017–2022): Software 2.0 in Production
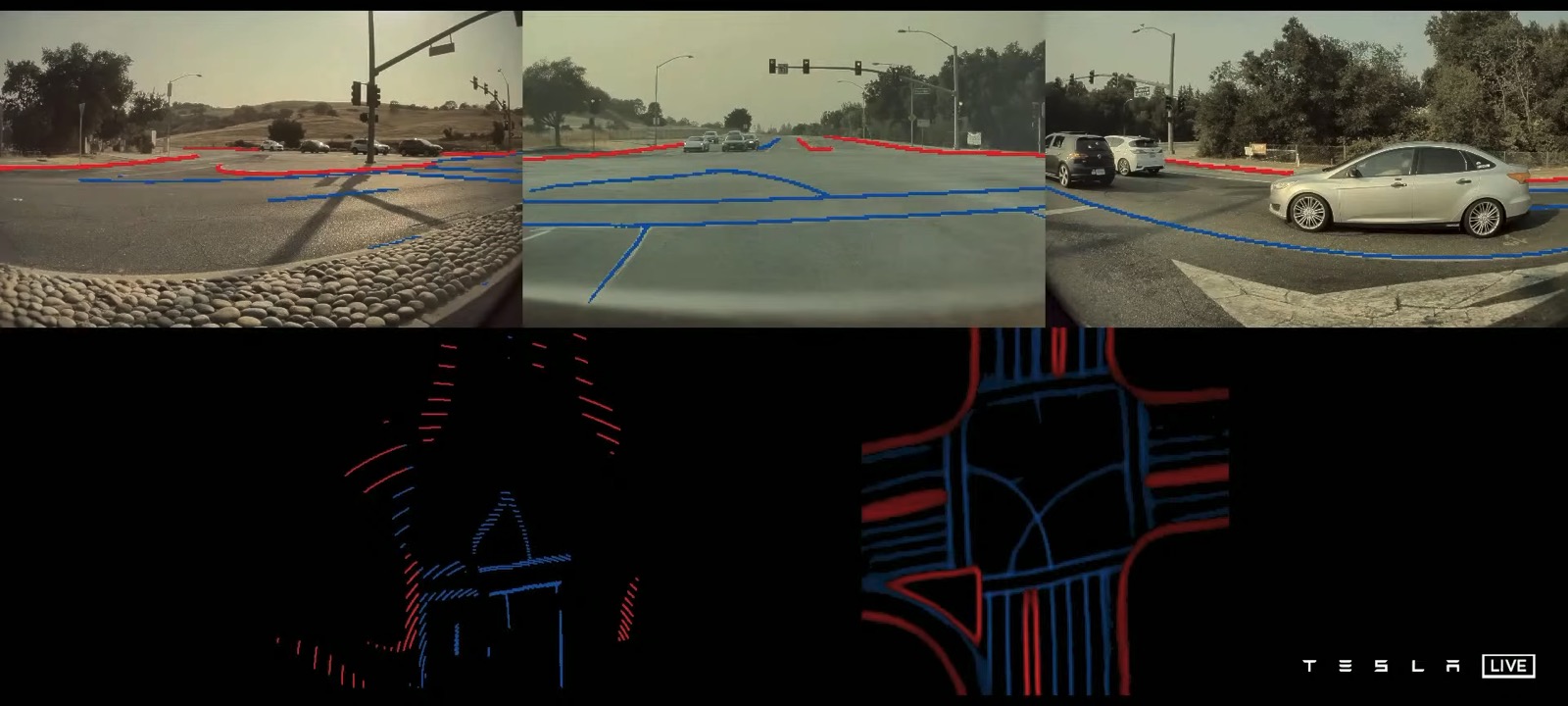
As Director of AI at Tesla, Karpathy ran Software 2.0 where the stakes were highest: a car moving at speed. The Autopilot vision system was a fleet of neural networks consuming camera feeds, and his team’s central problem was the one the essay predicted – when the program is the dataset, improving the program means improving the data. Tesla built data engines: pipelines that mined the fleet for the rare, hard cases (a truck carrying traffic cones, a deer at dusk), labeled them, retrained, and redeployed. The codebase shrank as hand-written heuristics were deleted and absorbed into the network. Karpathy described this directly as Software 1.0 code being “eaten” by the 2.0 stack – the clearest production validation of his thesis.2
nanoGPT, micrograd, and “Neural Networks: Zero to Hero” (2022–): From Scratch, Spelled Out

After Tesla, Karpathy turned full-time to the work that may outlast all of it: teaching people to build the stack themselves. His “Neural Networks: Zero to Hero” lecture series starts with micrograd – a complete automatic-differentiation engine and neural net library in about 100 lines of Python – and builds up, video by video, to a working GPT.6 The capstone lecture, “Let’s build GPT: from scratch, in code, spelled out,” reproduces the Transformer architecture from “Attention Is All You Need,” typed live. His companion build-nanogpt repository then reproduces GPT-2 (124M) from an empty file, with the git history kept clean enough to walk commit by commit – a working speedboat distilled from the production-grade nanoGPT.7
The pedagogy is the philosophy. There is no library import that hides the gradient. You implement backpropagation by hand so that when a real model misbehaves, you know – not believe – what is happening inside it. micrograd is the whole stack in 100 lines: no PyTorch, no magic, every multiply visible.
The Method
First principles, then frameworks. Karpathy refuses to let an abstraction stand until he has built the thing beneath it. micrograd exists so that PyTorch’s autograd is never a black box. Building the layer beneath is the engineer’s version of refusing to cite a source you haven’t read.
Build the smallest working version. char-rnn, micrograd, nanoGPT, and his more recent nanochat are all deliberately tiny – small enough to hold the whole thing in your head, complete enough to actually run. The smallness is the point: a 100-line library teaches what a 100,000-line one obscures.
Learn in public. Nearly everything Karpathy understands, he publishes – as a blog post, a lecture, a clean repo, a throwaway tweet that names a phenomenon (“vibe coding”) the rest of the field had felt but not articulated.8 The teaching forces the clarity; you cannot spell out backpropagation on a whiteboard while still confused about it.
Clarity as a tool of thought. The legibility of his demos – watching an RNN learn syntax character by character – is not showmanship. It is how he debugs his own understanding. If he can’t make it visible, he doesn’t yet understand it.
Influence Chain
Who Shaped Him
Geoffrey Hinton lit the fuse. Karpathy encountered backpropagation and neural nets through Hinton’s orbit at Toronto, at the precise moment – just before the 2012 ImageNet result – when the field tipped from fringe to dominant. The conviction that neural networks were not a niche tool but the future of computing is Hinton’s, carried forward.
Fei-Fei Li shaped the craftsman. As his PhD advisor and the architect of ImageNet, she gave Karpathy the discipline of treating data as the central object – the dataset as the thing that determines what a model can become. Software 2.0 is, in a real sense, the doctrine of a data-centric vision lab written out as a theory of all software.
Who He Shaped
A generation of ML engineers. CS231n was, for years, the way working engineers learned deep learning; its notes are still cited like a textbook. “Neural Networks: Zero to Hero” and nanoGPT then became the canonical from-scratch path into Transformers – the route thousands of practitioners took from “I use the API” to “I understand the architecture.” Few people have personally onboarded more of the current AI workforce.
The Throughline
John Carmack reverse-engineered graphics hardware and rebuilt the rendering pipeline from scratch because he would not ship on top of a layer he didn’t understand. Karpathy implements backpropagation by hand for the same reason. Both treat building it yourself not as a tutorial exercise but as the only honest path to mastery – the conviction that you do not truly know a system until you have written its smallest complete version. The same instinct runs through Linus Torvalds and his refusal to trust what he can’t inspect. (Series bridge)
What I Take From This
The discipline I keep returning to is Karpathy’s refusal to operate on top of a layer he hasn’t built at least once. When you’re composing agents, it’s tempting to treat the model as an oracle and the framework as gospel. His example says: build the smallest version yourself first – understand why the agent should call the model directly before you reach for the orchestration library. The Software 2.0/3.0 framing also reframes the whole job: in an agent system, you are not writing behavior, you are shaping the conditions – the context, the data, the prompts – under which behavior emerges, the throughline of everything from RAG to agents. The full map lives in the AI engineering hub and the agent architecture guide.
FAQ
What is Andrej Karpathy’s “Software 2.0”?
Software 2.0 is Karpathy’s term, from a 2017 essay, for programs written as the weights of a neural network rather than as explicit human-authored instructions. In Software 1.0 a programmer writes the logic; in Software 2.0 the programmer specifies a goal and an architecture, curates a dataset, and “the process of training the neural network compiles the dataset into the binary.” The dataset becomes the source code and training becomes compilation.1
What did Andrej Karpathy do at Tesla?
From 2017 to 2022 Karpathy was Tesla’s Director of AI, leading the neural-network vision stack behind Autopilot. His team built “data engines” that mined the vehicle fleet for rare, difficult driving scenarios, relabeled and retrained on them, and progressively replaced hand-written driving heuristics with learned networks – a production demonstration of his Software 2.0 thesis.2
What is “Neural Networks: Zero to Hero”?
It is Karpathy’s free video lecture series that teaches deep learning by building it from scratch in Python. It starts with micrograd – a ~100-line automatic-differentiation engine – and works up through language models to a from-scratch GPT, including the lecture “Let’s build GPT: from scratch, in code, spelled out.” The companion build-nanogpt repository reproduces GPT-2 (124M) starting from an empty file, one git commit at a time.67
Did Andrej Karpathy coin the term “vibe coding”?
Yes. In a February 2025 post on X, Karpathy described “a new kind of coding I call ‘vibe coding,’ where you fully give in to the vibes, embrace exponentials, and forget that the code even exists,” made possible by LLM coding tools getting good enough to build software by conversation. He later called the post a “throwaway tweet”; the term nonetheless entered the industry vocabulary.8
Sources
-
Andrej Karpathy, “Software 2.0.” Medium, November 11, 2017. “Neural networks are not just another classifier…They are Software 2.0”; “the process of training the neural network compiles the dataset into the binary”; “no human is involved in writing this code.” ↩↩↩↩
-
“Andrej Karpathy.” Wikipedia. Born Bratislava 1986; Toronto, UBC, Stanford PhD under Fei-Fei Li (2015); OpenAI founding member; Tesla Director of AI (2017–2022); return to OpenAI (2023); Eureka Labs (2024); Anthropic pretraining (2026). ↩↩↩↩
-
Andrej Karpathy, personal site / bio. CS231n: Stanford’s first deep-learning class, designed and primarily taught by Karpathy; enrollment grew 150 (2015) to 750 (2017). Course: CS231n. ↩
-
Andrej Karpathy, “The Unreasonable Effectiveness of Recurrent Neural Networks.” May 21, 2015. Character-level RNNs generating Shakespeare, LaTeX, Linux source, and Wikipedia markup; char-rnn code released on GitHub. ↩
-
Andrej Karpathy, “The hottest new programming language is English.” X, January 24, 2023. Extended in his 2025 talk “Software Is Changing (Again)” / Software 3.0. ↩
-
Andrej Karpathy, “Neural Networks: Zero to Hero.” Lecture series building neural networks from scratch, starting with micrograd. Repo: nn-zero-to-hero. micrograd (~100 lines, MIT-licensed): karpathy/micrograd. ↩↩
-
Andrej Karpathy, “build-nanogpt.” “Video+code lecture on building nanoGPT from scratch” – reproduces GPT-2 (124M) from an empty file with clean, step-by-step git commits you can walk through. Distilled from the production-grade repo: nanoGPT, “the simplest, fastest repository for training/finetuning medium-sized GPTs.” ↩↩
-
Andrej Karpathy, “There’s a new kind of coding I call ‘vibe coding’…” X, February 2, 2025. Later described as a “throwaway tweet.” ↩↩